This post is an overview of my amazon research project which I’ve been working on for a while now. I decided to share some of my thoughts and insights here, hoping that it might be inspiring for anyone interested. Especially the score building section is the result of hours of thinking and discussions about first principles of competition in a market. I hope you enjoy.
Table of content
-
The idea
-
Generating Product Niche Titles
-
Collecting, tagging and cleaning the data
-
Exploring the data
-
Building a score for finding the gaps
-
Results
The Idea
More than %60 of amazon retail sales revenue comes from individual third party merchants. It’s called amazon FBA (fulfillment by amazon). Think millions of products in different niches. My goal is to first understand the competition in these niches and then try to find the gaps in the competition all over the market.
There are no public datasets for the niches, products, or sales data. I had to gather around the data from multiple sources. It started with using NLP tools for coming up with, and validating tens of thousands of niche titles. Then I collected data on different product features such as category, title, and price. And finally the sales data which is most important piece of the puzzle. It all goes together in the score building process. I’ve used simple statistics tools and reward/penalize functions for evaluating the demand and supply in these niches, and building a score for each of them.
Generating Product Niche Titles (NER with Spacey and BERT)
Think of all the businesses and individuals selling stuff on their own websites ( shopify, woocommerce, … ) or on marketplaces like ebay or amazon. Countless numbers of products being uploaded on these platforms every single second.
Most of this data is very well structred. there is a product title, description, price, images, reviews, and etc. It is all well categorized and tagged. And yet it is not that easy to extract the categories and niches of these products. There’s no specific feature in the well structured data to tell us what a product actually is. In this post I’ll go through how i went about extracting these niche titles out of product titles.
I need these niche titles for my other project. I tried 4 different ways for getting the titles. scraping the titles, spacy , Google’s NLP and finally building my own NER with BERT.
Here is a summary of these trials:
Ready to use labeled titles
before using NER for extracting niche titles from product titles, let’s first see if there’s an easier way for finding these niches: https://www.buzzfeed.com/shopping
There is a lazy load of countless product reviews on buzzfeed. take a close look at these articles and you’ll immediately see the pattern.
So there it is. a large number of niche titles, all hand labled.
I wrote a script for scraping these for my other amazon data analysis project. here is a quick guide for that. start with buzzfeed.com/us/feedpage/feed/shopping-amazon?page {}&page_name=shopping and get the links for the articles.
def get_buzzfeed_articles():
url = "https://www.buzzfeed.com/us/feedpage/feed/shopping-amazon?page={}&page_name=shopping"
articles = []
for page in range(2,20):
browser.get(url.format(page))
rows = browser.find_elements_by_class_name("js-card__link")
for row in rows:
article_link = row.get_attribute("href")
articles.append(article_link)
return articles
def check_product_price(product_text):
try:
myprice= re.findall(r"(\d+\.\d{1,2})",product_text)[0]
myprice = float(myprice)
if myprice > 15 and myprice <60:
return True
except:
return False
def get_products_from_article(article_url):
browser.get(article_url)
product_wrapper = browser.find_elements_by_class_name("subbuzz")
products = []
for product in product_wrapper:
try:
product_title = product.find_element_by_class_name("js-subbuzz__title-text")
myproduct = {}
mylink_tag = product_title.find_element_by_tag_name("a")
mylink = mylink_tag.get_attribute("href")
if not check_product_price(product.text):
continue
source_product_name = product_title.find_element_by_tag_name("a").text
if mylink.startswith( 'https://www.amazon.com/dp' ):
amazon_asin = mylink[26:36]
myproduct["asin"]= amazon_asin
myproduct["source_product_name"] = source_product_name
products.append(myproduct)
except:
pass
return products
It is always nice to tag the source of the scraped data so that we can use it later in the data cleaning and processing stage.
for product in products :
product["source"]="buzzfeed_price_15_to_60"
product["scraping_status"]="queue"
requests.post(url,json=product)
Using Spacy’s “en_core_web_lg” model
spacy could tag 638 “PRODUCT” entities out of 20k product titles on en_core_web_lg and 129 on en_core_web_sm.
import spacy.cli
spacy.cli.download("en_core_web_lg")
nlp = spacy.load("en_core_web_lg")
f = io.BytesIO(uploaded['titles.csv'])
products_value = f.getvalue()
products = str(products_value).split("\\n")
mined_niches = open("spacey_ner_niches.csv","w")
qualified_niches = []
for i in range(len(products)) :
text = products[i].split(",")[1]
doc = nlp(text)
for entity in doc.ents:
if entity.label_ == "PRODUCT":
title = entity.text
title_words = len(title.split(" "))
if title_words >1 and title_words <8 and not re.search(r"\d",title):
if title not in qualified_niches:
qualified_niches.append(title)
mined_titles.writelines(title+"\n")
Google’s NLP API
google got about 3200 “CONSUMER_GOOD” entities our of 20k product titles.
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=" "
client = language.LanguageServiceClient()
text = products[i].split(",")[1]
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
entities = client.analyze_entities(document).entities
for entity in entities:
entity_type = enums.Entity.Type(entity.type)
try :
if entity_type.CONSUMER_GOOD:
if entity_type.name == "CONSUMER_GOOD":
niche = entity.mentions[0].text.content
niche_words = len(niche.split(" "))
if niche_words >1 and niche_words <8 and not re.search(r"\d",niche):
if niche not in qualified_niches:
qualified_niches.append(niche)
mined_niches.writelines(niche+"\n")
...
here are some of extracted niches:
Protractor Set
Box Lathe Tool
Hobby Bead Craft Tools
Trigger Spray Bottle
Crystal Plastic Lid Cover
Acrimet Magazine File Holder
Acrimet Premium Metal Bookends
Acrimet Stackable Letter Tray
TimeQplus Proximity Bundle
Acroprint BioTouch
Clear Parts Storage Box
...
Building my own training dataset with prodcut tags
I was curious about training my own NER model for recognizing PRODUCT entities. I started searching for NER training datasets with product tags in them. I found a dataset of best buy products tagged with Category, Brand, ModelName, ScreenSize, RAM, Storage, and Price. I couldn’t download the dataset though. It seems to be deleted for some reason!
I did a lot of googling but i couldn’t find a public dataset with product tags in it. I decided I still wanted to train my own NER for its fun at least. and then see if I can also build my own dataset using the data i collected from buzzfeed. I followed this awesome tutorial and trained a model on CoNLL2003 with BERT and using sparknlp.
I also found a related paper which is using Amazon review dataset for annotating products in the reviews.
I couldn’t understand how they’ve exactly annotated the so-called Components. but I thought of something similar myself. I had an idea for using CoNLL2003 to annotate entities in 20k product titles. except that there would be no product tags in the training data. which i could provid using my own product labels from my own buzzfeed dataset.
Here is the format of eng.train in CoNLL2003 :
-DOCSTART- -X- O O
Goldman NNP I-NP I-ORG
Sachs NNP I-NP I-ORG
sets VBZ I-VP O
warrants NNS I-NP O
on IN I-PP O
Continental NNP I-NP I-ORG
. . O O
LONDON NNP I-NP I-LOC
1996-08-23 CD I-NP O
So for example look at this product on buzzfeed shopping:
The amazon link is to a product with the title: “Maytex 50681 Mesh Pockets Shower Curtain Or Liner”. we can search it on amazon and collect hundreds of similar product titles with the same niche. And here is the predictions of the model I trained on CoNLL2003:
Maytex NNP NNP B-ORG
50681 CD CD O
Mesh NNP NNP O
Pockets NNP NNP O
Shower NNP NNP O
Curtain NNP NNP O
Or CC CC O
Liner NNP NNP O
{'document': ['Maytex 50681 Mesh Pockets Shower Curtain Or Liner'],
'embeddings': ['Maytex',
'50681',
'Mesh',
'Pockets',
'Shower',
'Curtain',
'Or',
'Liner'],
'ner': ['B-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O'],
'ner_chunk': ['Maytex'],
'pos': ['NNP', 'CD', 'NNP', 'NNP', 'NNP', 'NNP', 'CC', 'NNP'],
'sentence': ['Maytex 50681 Mesh Pockets Shower Curtain Or Liner'],
'token': ['Maytex',
'50681',
'Mesh',
'Pockets',
'Shower',
'Curtain',
'Or',
'Liner']}
Now I have the labels for Shower and Curtain which I can replace B-PRODUCT and I-PRODUCT. Then I can write it back to a new train dataset, which i should be able to use for training the new model. I’m not sure if it would be worth the effort so I stopped here and moved on with my amazon research project.
Active learning with prodi.gy and buzzfeed’s hand labeled data
Training nlp models require lots of labeld data and I don’t know of any available NER datasets with “product” tags. and that is where active learning comes in. So here is the idea:
using active learning for fine-tuning a model using the hand labled data which we got from Buzzfeed. For each niche title we can collect hundreds of product titles related to that niche from amazon. then we can improve an existing general purpose spacy model like “en_core_web_lg” (which does have the PRODUCT tags included) with correcting it’s predictions and adding the entities which spacy is missing out.
prodigy is a pretty expensive tool and i didn’t get to try it out.(and google nlp results were good enough for my amazon research project). but I think active learning on buzzfeed’s labeled data might have got us the top results compared to all other methods discussed in this post.
Collecting, tagging and cleaning the data
The data has been collected from multiple sources such as amazon, estimations on product sales numbers, and also keyword search data. I’ve built a pipeline and a tag management tool which was used by crawlers on multiple machines, working with a Django Rest API. These crawlers ask the rest api for a niche, product, or keyword to crawl. These scraping tasks are put in a queue, get crawled and finally submitted to the DB.

Product Niche titles
The titles are extracted from hundreds of thousands of product titles. I have made another post explaining how i tried different approaches for the NER process. here are some examples of the niches extracted:
Protractor Set
Box Lathe Tool
Hobby Bead Craft Tools
Trigger Spray Bottle
Crystal Plastic Lid Cover
Acrimet Magazine File Holder
Acrimet Premium Metal Bookends
Acrimet Stackable Letter Tray
TimeQplus Proximity Bundle
Acroprint BioTouch
Clear Parts Storage Box
...
I did most of my analysis in Jupyter notebooks. Here I share small pieces of that.
The data is in 3 different tables for niches, products and keywords. Now let’s load them and take a look.
niches = pd.read_sql_query("SELECT * FROM rest_subniche",conn)
products = pd.read_sql_query("SELECT * FROM rest_product",conn)
keywords = pd.read_sql_query("SELECT * FROM rest_keyword",conn)
These niches are picked randomly, from a wide spectrum of product titles. This gives us all the major categories.
Beauty & Personal Care 529
Automotive 508
Clothing, Shoes & Jewelry 242
Tools & Home Improvement 105
Home & Kitchen 88
Health & Household 87
Sports & Outdoors 45
Industrial & Scientific 33
Toys & Games 30
Office Products 30
Electronics 24
Cell Phones & Accessories 22
Patio, Lawn & Garden 20
Kitchen & Dining 18
Pet Supplies 18
Grocery & Gourmet Food 13
Baby 12
Books 8
Arts, Crafts & Sewing 8
Musical Instruments 4
Computers & Accessories 3
Camera & Photo 3
Appliances 2
Name: category, dtype: int64
Cleaning the data and reliability
After some experimenting and thinking about multiple strategies for data cleaning, I decided I need to filter out a big chunk of the data, containing empty values and nulls. I tried replacing them which makes the score less reliable and makes things complicated . We don’t want to let loosely supported niches leak into our score building process.
products[num_columns].isna().sum()
price 5830
margin 5779
sales 6609
revenue 6730
bsr 6564
reviews 1
weight 3832
number_images 3940
rank_position 3720
dtype: int64
And finally we end up with 394 niches left after dropping empty and null values.
products.dropna(axis=0,how="any",inplace=True)
products.shape
~~(~~1852, 17)
products.mother_niche_id.unique().size
394
Exploring the data
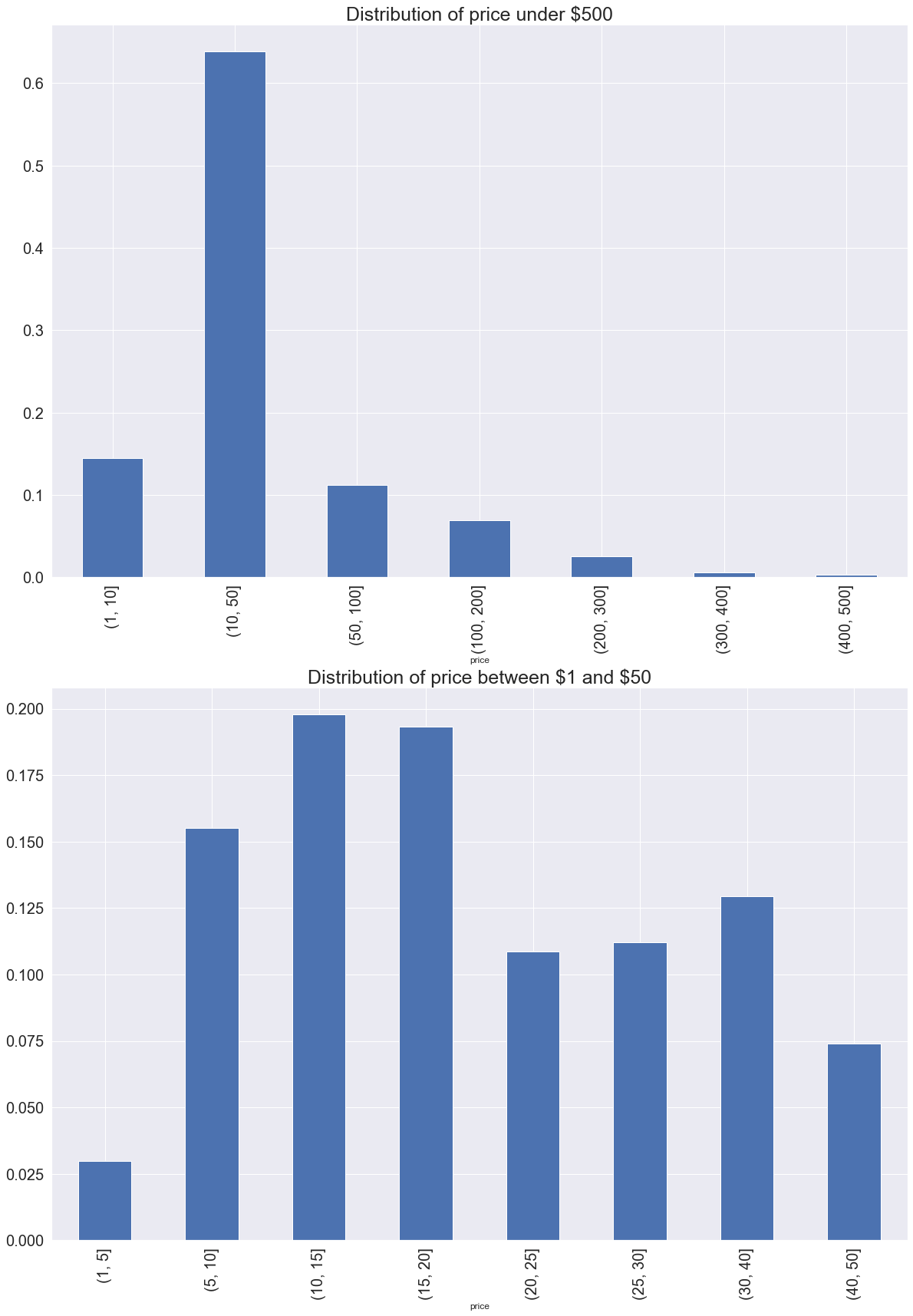
distributions
Looking into the distribution of prices, revenues and reviews helps us develop some sort of an intuition for building the score.Let’s look into some plots.




Scatter of reviews and revenues
revenue_reviews_scatter = products[(products["revenue"]<100000)&(products["reviews"]<1000)]
revenue_reviews_scatter[["reviews","revenue"]].plot(x="reviews",y="revenue",kind="scatter",ax=ax

Building a score for finding the gaps
The intuition behind the formula for the score is based on simple supply and demand economics of a market. We’re trying to find the niches with highest revenues and lowest number of reviews. Then there are other factors which we have to be careful about. We have to watch out for monopolies where few sellers have dominated the niches We’re looking for high volume of monthly searches. We need to avoid high variance across sales and reviews numbers.
Here is a simple list of the main elements going into the score:
-
Counting the the products within a specific range of revenue and review
-
Revenue/Review ratios
-
Ranking weights and confidence score
-
Penalizing niches for too much Variance
-
Penalizing the toxic niches with a few sellers in a monopoly position
-
Search demand ( Exact Match Volumes), sponsored ads and biddings
Counting products in the range
Counting is the core of our score building strategy. It’s simply a count of products within our desired band of revenue and review.
def count_score(niche_products):
...
return niche_products[(niche_products["revenue"]>Count_min_revenue) &
(niche_products["reviews"]<Count_max_review)].shape[0] / niche_products.shape[0]
Comparing revenue/review ratios to the median
revenue/review ratios is the second most important part of the score. We set an upper and lower band around median of all revenue/review ratios , and compare each one to those bands which maps them to [ _1 , 0 , 1] . We then use the mean of those baselined ratios as our ratio_score.
...
ratio_baseline = products["revenue/reviews"].median()
...
def compare_to_baseline(niche_products):
baselined_ratios = []
band = 0.2
upper_band = (1+band) * ratio_baseline
lower_band = (1-band) * ratio_baseline
for i, product in niche_products.iterrows():
....
if lower_band < product["revenue/reviews"] < upper_band :
baselined_ratios.append(0)
elif upper_band < product["revenue/reviews"] :
baselined_ratios.append(+1*product_rank_weight)
elif lower_band > product["revenue/reviews"] :
baselined_ratios.append(-1*product_rank_weight)
...


ranking the niches
count_score, ratio_score and other building blocks of the score discussed above are aggregated into a single score, which is then used for ranking the niches.

Feel free to contact me if you find the collected data or the tool useful for your specific use cases.
cheers